Отрывок из книги «Корпоративные Хранилища Данных». Глава 7 «Повышение Качества Информации в Хранилищах Данных»
Предлагаем для ознакомления главу 7 «Повышение Качества Информации в Хранилищах Данных» из книги «Корпоративные Хранилища Данных. Том 1. Планирование, Разработка, Реализация», автора Эрика Спирли.
В этой главе автор обращает наше внимание на важность обеспечения высокого качества данных в хранилищах данных. Описывается значимость роли, которую играет качество данных в успехе создания хранилища, и необходимость обеспечения качества данных.
Глава начинается с показательного примера, описывающего подсчет ущерба, нанесенного компании использованием некорректных данных. Описывается метод, направленный на достижение высокого качества данных.
* * *
Напоминаем, что авторские права охраняются законом и данные материалы предоставлены исключительно в ознакомительных целях!
* * *
Глава 7. Повышение качества информации в хранилищах данных
7.1. Введение
Как вы помните из главы 1, одна из основных причин построения хранилища данных – обеспечить возможность интеграции данных из многих унаследованных систем. Перед внедрением СППР или системы хранилищ данных руководители секторов и подразделений организации могут подготовить ряд отчетов, отражающих различные показатели состояния бизнеса. Эти отчеты вырабатываются с помощью разных систем либо с использованием процедур генерации отчетов одной и той же системы. Иногда различные значения одних и тех же показателей в нескольких отчетах получаются из-за различия в методах генерации отчетов, в то время как в других случаях причина кроется в разных значениях исходных данных или неверных значениях данных в различных унаследованных системах. Хотя хранилище может помочь преодолеть проблему разобщенных источников данных, оно неспособно решить проблему неверных или некачественных данных в оперативных системах. Этого можно достичь с помощью программы повышения качества данных, которая составляет предмет обсуждения данной главы.
Низкое качество данных – одна из наиболее трудных для разрешения проблем при конструировании хранилища. Хотя большинство неудач проектов хранилищ данных может быть отнесено на счет проблем, связанных с процессами, вопросы качества данных системы-источника должны рассматриваться как часть процесса конструирования хранилища данных. Даже когда методология хранилищ данных и проектный план включают эти вопросы, проблемы с качеством данных системы-источника, как правило, оказываются сложнее и требуют больше времени, чем можно было предусмотреть вначале. По своему опыту автор знает, что проблемы, относящиеся к общему качеству данных, наиболее часто являются причиной увеличения сроков проекта.
Для повышения качества информации в хранилище данных могут использоваться различные подходы и методы. На первом этапе выполнения программы повышения качества требуется выяснить, как обстоит дело с качеством данных в системах- источниках. После того как источники проблем установлены, необходима разработка методов повышения качества данных. Один из способов повысить качество данных в хранилище заключается в повышения их качества в системах-источниках. Другой способ – коррекция данных при их перемещении из унаследованной системы в хранилище. Хотя теоретически все это выглядит довольно просто, на деле приверженность организации повышению качества данных в хранилище требует непрерывного повышения качества информации в рамках всего предприятия.
Почему мы используем термин повышение качества информации? Цель хранилища данных – обеспечить обоснованные ответы на деловые вопросы. Чтобы достичь этой цели, мы должны не только поместить надлежащие биты информации в подходящие поля, но и снабдить значения данных в этих полях строгими определениями. Только обладая исчерпывающими определениями полей данных, мы будем в состоянии установить, верны ли данные, которые хранятся в этих полях. Выявив уровень качества данных в полях, можно внедрять процесс очистки данных, загружаемых в хранилище. Аналогично могут быть введены и другие процессы, направленные на повышение качества определений данных и качества данных в системах- источниках. Результатом интеграции уточненных источников и определений данных в хранилище является более качественная информация в форме данных и определений, надлежащим образом интегрированных в хранилище.
Процесс повышения качества информации в рамках предприятия состоит из нескольких взаимосвязанных этапов. Этот процесс показан на рис. 7.1. На первом этапе определяется ценность качества информации для предприятия. Неверная информация связана с издержками для предприятия, которые также необходимо оценить. Далее можно установить качество определений данных для предприятия, а затем определить качество собранных данных. После того как качество и сложность определений данных и хранимых данных установлены, можно приступить к разработке процесса повышения качества информации в масштабах предприятия.
Этот процесс должен быть нацелен не только на очистку данных, которые загружаются в хранилище, но и на повышение качества определений и данных, которые хранятся в унаследованных системах. Высокоуровневая концептуальная схема информационных потоков в хранилище данных была впервые введена в главе 1 и повторно приводится на рис. 7.2. Важно помнить, что унаследованные системы являются источниками как данных, так и информации о данных, или метаданных.
Программа повышения качества информации, с которой работает предприятие, – это проект, масштабы которого зачастую могут казаться пугающими. При выполнении подобного проекта очень важно руководствоваться теми же принципами, которые применимы к проектам по быстрой разработке приложений. Подобный проект лучше всего начинать с поиска спонсора, заинтересованного в повышении качества информации. Этот спонсор должен обладать возможностями по финансированию проекта и понимать, что вложение средств в мероприятия по обеспечению качества информации окупает себя. Спонсор также должен наделить необходимыми полномочиями менеджера проекта по повышению качества информации. Эти полномочия бывают зачастую практически неограниченными, и менеджер проекта играет роль диктатора во всех вопросах, касающихся обеспечения качества информации.
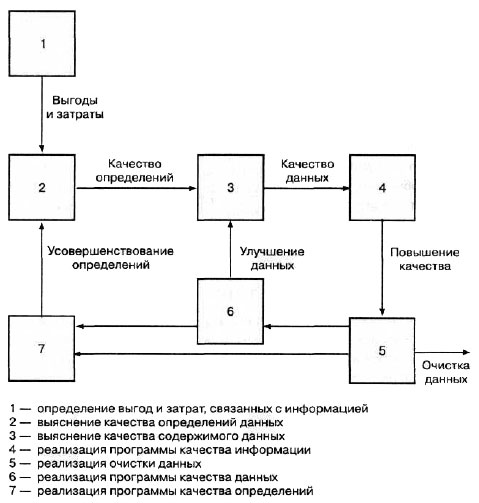
Рис. 7.1. Последовательность процесса реализации программы повышения качества информации
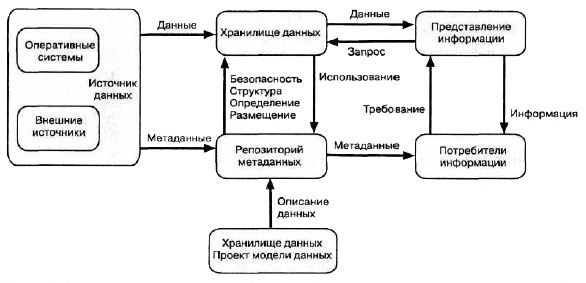
Рис. 7.2. Унаследованные системы должны быть источником качественных данных и метаданных для хранилища
Определив спонсора и "босса по качеству", на следующем этапе программы необходимо выявить данные, которые имеют критическое значение для успеха проекта хранилища. Это можно осуществить во время одного из JAD-совещаний по хранилищу данных. На совещании должен быть выработан перечень данных, имеющих решающее значение для успешного выполнения хранилищем своих функций. Во время JAD-совещания можно приблизительно оценить требуемые уровни качества данных, а также потери, связанные с их низким качеством. Программа повышения качества информации может осуществляться параллельно с построением модели данных хранилища. После того как разработчики приступили к моделированию данных, должны быть определены элементы хранилища данных, а также источники записей. Кроме того, необходимо выполнить упомянутую в главе 3 оценку прогнозного разрыва, чтобы установить разрыв между качеством данных в оперативной системе и качеством, требующимся для хранилища данных. Затем необходимо разработать план повышения качества данных до требуемого уровня и определить стоимость реализации плана. После этого спонсор в области качества информации должен оказать поддержку программе повышения качества данных и другим секторам организации, так или иначе задействованным в этой программе.
Программа в области качества информации аналогична любой из программ в сфере управления абсолютным качеством. Поэтому уроки, извлеченные из программ абсолютного качества, и используемые в ходе их выполнения средства могут оказаться полезными для программы в области качества данных. Среди прочих полезных средств стоит упомянуть диаграммы Парето, анализ влияния факторов при прогнозировании и цикл Шьюхарта (Shewhart): планирование, выполнение, проверка и корректирующие действия.
7.2. Значение качества информации для успеха организации
Оценить значение качества информации для успешной деятельности организации и выгоды, обеспечиваемые определенным уровнем этого качества, можно разными способами. Прежде всего следует заметить, что выгоды от использования качественных данных могут быть как ощутимыми, так и неощутимыми. Очевидно, что решения, принимаемые руководителями организации, не могут быть лучше той информации, на которой они основываются. Хотя лучшая обоснованность решений и являет собой очевидную потенциальную выгоду от использования более качественной информации, подсчитать отдачу, которую сулит эта выгода, довольно трудно. Тем не менее в некоторых случаях выгоду от работы с более качественной информацией можно вычислить. Например, мы все получаем рекламные послания по почте. Ошибки в данных, использованных для генерации этих посланий, приводят либо к возврату почты, либо к неверной доставке. Например, получая почтовые послания с явными ошибками в имени, многие бросают их в мусорную корзину нераспечатанными. Эта проблема качества информации находит свое выражение в определенных потерях, связанных не только с почтовыми расходами на обращение, которое было проигнорировано, но и в затратах, связанных с упущенной возможностью вступить в контакт с потенциальным потребителем.
К вопросу добычи данных мы обратимся позже в этой книге. Целью добычи данных является поиск закономерностей а данных. Возможность автоматизации процесса поиска закономерностей в данных решающим образом зависит от их качества. Например, обнаружение случаев мошенничества основано на идее, что мошеннические действия обладают некоторыми характеристиками, которые отличают их от обычных событий. Запись события с неверными данными обладает характеристиками, отличными от свойственных обычному случаю. Таким образом, неверные данные могут быть неотличимы от данных, представляющих мошеннические операции, и делают невозможным автоматическое обнаружение случаев мошенничества. В подобной ситуации цена некачественных данных может оказаться слишком высокой.
Данные становятся полезными после переработки на "информационной фабрике" организации. Например, данные о заказе от клиента очень важны, поскольку позволяют организации исполнить заказ, однако ценность данных заказа ограниченна. После того как данные по заказу объединяются с данными по доставке, данными по клиенту, демографическими данными потребителей и данными о платеже, они становятся крайне ценной информацией. Эта цепочка показана на рис. 7.3.
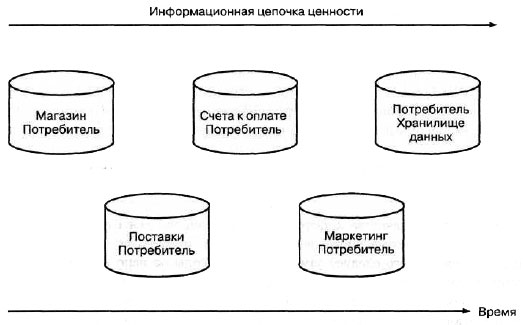
Рис. 7.3. Цепочка ценности информации
По мере того как данные распространяются по цепочке информационной ценности организации, вместе с ними могут распространяться и ошибки, причем их масштабы в ходе интеграции и превращения в информацию могут возрастать. Например, если кассовый терминал магазина фиксирует неверный идентификатор потребителя, то данная операция будет ошибочно связана с неким клиентом. По мере того как данные объединяются в хранилище, им ставится в соответствие другая, также ошибочная, информация по операции продажи, исходя из неверного идентификатора клиента. Все это демонстрирует, насколько важно выявлять и исправлять ошибки на самых ранних этапах жизненного цикла данных.
7.3. Трудности на пути получения качественных данных
Зачастую собрать и поддерживать в актуальном состоянии качественные данные довольно трудно, это может быть обусловлено разными причинами. Как вы помните из главы 2, ИТ-подразделения в своей деятельности опираются на четыре "столпа", которые несут на себе всю тяжесть повседневных задач. Это люди, процесс, стратегия и технология. Поэтому вполне естественно, что одни трудности связаны с проблемами процесса, другие – с человеческим фактором, а третьи вызваны технологическими проблемами. Независимо от того, что является источником проблемы с качеством данных, важно выявить этот источник и по возможности найти решение.
Проблемы получения качественных данных могут быть вызваны многочисленными техническими причинами, что, как правило, свойственно современным унаследованным системам. Одна из причин заключается в отсутствии сколько-нибудь ясно выраженной архитектуры у некоторых систем. Эти унаследованные системы разрабатывались в течение длительного времени без какого-либо плана дальнейшего развития. По мере эволюции на них ставились все новые и новые "заплатки" для добавления новых функциональных возможностей или изменения существующих функций. Зачастую это приводило к ситуациям, при которых введенные данные строго не проверялись на корректность. В этом случае ошибки при вводе данных не обнаруживались и не исправлялись на ранних этапах жизненного цикла данных.
Кроме того, принципы архитектуры данных, проектирования реляционных баз данных и нормализации в прошлом не имели широкого распространения. Это приводило к тому, что правила в отношении данных чаще встраивались в унаследованный программный код, чем представлялись в виде отдельного компонента самих данных. Например, программа может использовать одно и то же поле для хранения данных, имеющих разный смысл, в зависимости от их значения. Хотя это и способствовало сбережению необходимого объема памяти, но значительно затрудняло верификацию правильности введенных данных.
Как отмечалось в главе 1, большинство унаследованных систем разрабатывались с целью выполнения конкретных задач для разных функциональных подразделений. Эти унаследованные системы строились таким образом, чтобы удовлетворять требования определенной функциональной области без учета потребностей других областей или корпоративной системы отчетности. Не существовало какого-либо общего плана совместного использования данных одного информационного бункера в другом. Подобная ситуация проиллюстрирована на рис. 7.4.
Чтобы обеспечить распространение данных из одной системы в другую, необходимо разработать и использовать общие уникальные идентификаторы или ключи в элементах данных различных систем. Это обеспечивает совпадение записей в различных системах при совпадении уникальных идентификаторов этих записей. Код социального обеспечения используется в США во многих информационных системах для уникальной идентификации личности. При отсутствии уникальных идентификаторов для сопоставления записей необходимо использовать некоторые другие менее надежные методы. Это приводит к ошибкам в данных в других системах из-за ошибок в сопоставлении записей данных, которые переносятся в них.
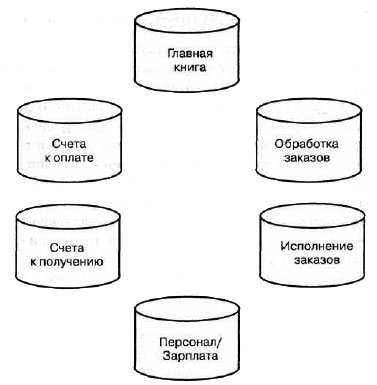
Рис. 7.4. Отсутствие связей между бункерами данных порождает ошибки в производных данных
Проблемы, связанные с процессом, зачастую вызваны данными, которые вводятся в оперативную систему в неподходящей точке процесса эксплуатации. Кроме того, эти проблемы зачастую порождаются отсутствием понимания смысла данных оперативной системы и способов разрешения связанных с ней вопросов. Обе эти проблемы могут быть сняты за счет обучения и использования функций оперативной помощи пользователю. Проблемы, связанные с процессом, можно также ослабить за счет повышения уровня осведомленности сотрудников о значении качества для работы организации и поощрения людей за качественную работу.
Проблемы, связанные с человеческим фактором, обычно вызваны недопониманием роли качества в работе организации или неверной расстановкой приоритетов при выполнении работы сотрудниками. Если качество обработки данных определяется сочетанием скорости и точности обработки, трудности, связанные с вводом неверных данных операторами, можно уменьшить за счет смещения акцентов с низкой скорости обработки на ее качество. Весьма полезны в этом отношении системы, которые отслеживают данные, вводимые пользователем, поскольку позволяют измерить качество работы персонала.
Подведем краткие итоги. Существует множество причин возникновения неверных данных. Основной момент состоит в том, чтобы установить источники ошибок в данных и провести соответствующую работу в рамках развития корпоративной культуры и технической инфраструктуры для устранения причин этих ошибок.
7.4. Методы оценки выгод, получаемых за счет обеспечения высокого качества данных
Оценить выгоды, связанные с высоким качеством информации в хранилище данных, можно многими способами. Чтобы прикинуть, какую ценность представляет высокое качество данных в хранилище, крайне важно понять, как организованы данные и каково их значение для функционирования организации. Издержки, обусловленные низким качеством данных, также могут выступать мерой ценности высококачественных данных для организации.
Примером ценности качества данных может служить концепция ценности жизненного цикла потребителя (Под жизненным циклом в данном случае понимается период, в течение которого потребитель остается клиентом компании. Под совокупной ценностью потребителя понимается стоимость всех приобретенных им товаров в течение указанного периода. Смотрите, например, книгу Дэвида Джоббера Принципы и практика маркетинга. – М.: Издат. дом "Вильяме", 2000 г. – Прим. ред.). Клиент бакалейного магазина может покупать в нем товары от семи до десяти лет подряд. В течение этого периода средний потребитель принесет доход, который эквивалентен единовременному платежу, полученному от него на сегодняшний день. Текущая ценность потребителя может составлять 1000 долларов. Предположим, что магазин рассылает рекламные обращения 4 млн. известных покупателей и 5% имен в списке рассылки содержат ошибки. Из 5% адресатов, которые получают рекламу с неправильным указанием имени, 2% настолько раздражены, что становятся клиентами другого магазина. Иными словами, 4000 потребителей сменили магазин из-за почтовой ошибки. Если совокупная ценность потребителя составляет 1000 долларов, то ошибка обходится примерно в 4 млн. долларов.
Другим примером ценности качества данных может служить реклама, которую мы получаем по почте. Предположим, что большая компания розничной торговли отправляет 50 млн. рекламных проспектов. Создание и отправка по почте каждого рекламного проспекта обходится в 60 центов. Если 7% адресов в базе данных неверны, то проблема ошибки в почтовом адресе обходится в 2,1 млн. долларов. Если 30% людей, которые не получили рекламный проспект из-за ошибки в адресе, могли бы приобрести товары, принеся средний доход в 75 центов, ошибка в адресе будет стоить 788 тыс. долларов упущенной выгоды.
Важным моментом при оценке стоимости ошибок в данных является глубокое понимание механизмов бизнеса и последствий этих ошибок для деловых операций. Приведенные выше примеры были посвящены розничной торговле, однако читатель может легко перенести их на другие деловые сферы.
7.5. За какое качество мы должны бороться
Если организация ставит целью достижение высокого качества данных, этот выбор должен основываться на фактах, однако в огромной мере он зависит от корпоративной культуры и философии. Некоторые организации убеждены, что практически все обнаруживаемые ошибки в данных должны быть найдены и исключены. Это часть философии организации. Миссия, система ценностей и цели организации должны содержать утверждение о том, что безупречное функционирование является существенной составляющей успеха организации.
В других организациях проблему обеспечения качества данных рассматривают в аспекте инвестиций в прибыльность. В этом случае хорошим способом определения предполагаемого уровня качества данных в хранилище является оценка предельного дохода на вложенный капитал. Эта концепция проиллюстрирована в табл. 7.1.
Таблица 7.1. Предельные издержки и предельный доход от устранения ошибок в данных
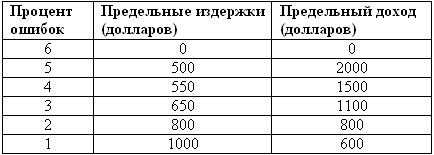
Основная идея предельных издержек состоит в том, что если мы вложили доллар, то по меньшей мере желаем вернуть его через некоторое время. В примере, приведенном в табл. 7.1, выбран трехлетний период окупаемости. Мы продолжаем инвестиции до тех пор, пока объем возвращенных средств остается равным (или меньше) объему вложенных средств. Аналогичный принцип применим в отношении вложений в качество данных. Строго говоря, в аспекте финансовой перспективы вложения в качество необходимо осуществлять до тех нор, пока предельный доход равен предельному объему инвестиций. Применительно к примеру, приведенному в табл. 7.1, снижение частоты ошибок с 6 до 2% соответствует выравниванию предельных издержек с предельным доходом на вложенный капитал.
7.6. Методы оценки данных
Для оценки текущего уровня качества данных существует несколько методов – как применяемых вручную, так и автоматизированных. Так, например, автор пользуется методом, при котором на экран выводится фрагмент данных. Человеческий разум – поразительная вещь: просто удивительно, насколько легко обнаружить нерегулярность в данных или метаданных. Автор обычно использует какое-нибудь имеющееся под рукой средство формирования запросов для выбора строк одной из важных таблиц, задавая при необходимости операцию ее соединения с другими таблицами. По мере прокручивания строк результата на экране легко заметить изменения в их характере, например связанные с длиной или значением. Это один из существенных способов познакомиться с данными и усвоить смысл данных, представленных с помощью браузера метаданных.
Еще один интересный способ вручную нащупать места возможных ошибок в данных состоит в выполнении специфических выборок данных. Например, автор ежемесячно получает почтовую корреспонденцию, в которой фамилия получателя имеет 10-12 разных вариантов. С помощью выбора имен из базы данных клиентов с использованием шаблона подстановки или аналогичного выражения в SQL-клаузе можно найти группу имен, которые были неверно введены в базу данных.
Еще один путь поиска возможностей улучшить положение дел с качеством данных в унаследованных системах – расспросить пользователей, программистов и системных аналитиков о том, что им известно о конкретных проблемах с данными. Зачастую в организации можно найти настоящий "кладезь знаний" о существующих проблемах с данными. При работе над несколькими проектами хранилищ данных автору довелось столкнуться с ситуацией, когда один из пользователей обращал внимание на тот факт, что несколько клиентов присутствуют в системе многократно под разными именами. Применив описанный выше прием выбора данных, удалось обнаружить, что один из клиентов был представлен в системе 27 раз.
Наконец, для исследования данных можно применить программные средства. Очевидным преимуществом использования ПО для того, чтобы "перерыть" данные, является возможность очень быстро исследовать огромные объемы данных заранее определенными способами. Одни программы прекрасно обнаруживают конкретные проблемы с данными, например такие, как ошибки почтовой адресации. Другие средства обладают более широкими возможностями и могут обнаруживать или обнаруживать и исправлять широкий спектр ошибок. Эти программы рассматриваются более подробно в следующем разделе.
7.7. Программные средства оценки качества данных
На сегодняшнем рынке представлен широкий спектр программных средств для оценки качества данных систем-источников, которые отличаются как набором функций, так и ценой. Вообще говоря, эти средства могут быть отнесены к одной из четырех категорий программ: аудита, очистки, профилактики и выведения закономерностей.
Программы аудита (audit program) осуществляют поиск в данных неполных записей, дублирующихся записей, неверных значений и отсутствия синхронизации данных в разных средах. Программа аудита сообщает об обнаружении проблемы и указывает количество и процент обнаруженных ошибок. Эта программа не "исправляет" и не "очищает" данные. После того как в данных установлено наличие некоторых проблем, программа очистки по возможности исправляет эти данные.
Программы выведения закономерностей (rule discovery program) устанавливают ряд структурных зависимостей в данных, которые охватывают как отношения между полями данных, так и допустимые значения полей данных, В качестве примера возможного отношения между элементами данных рассмотрим хорошо известное положение о том, что сокращение для названия штата также указывает на диапазон ZIP-кодов (Zone Improvement Program Code – почтовый индекс в США). Например, код штата OR для Орегона может указывать на то, что ZIP- код должен лежать в диапазоне от 97000 до 97200. Примером ограничения на значение поля может служить почтовый код США, который должен принадлежать множеству (АК, AL, ...,WY).
Программы очистки (cleansing program) данных выявляют ошибки и исправляют их. Ошибки в данных идентифицируются с помощью правил, которые заранее заданы в программе очистки, выводятся с помощью этой программы или определяются комбинацией этих двух случаев, Когда программа обнаруживает нарушение правил, она использует правила для устранения проблемы.
Программы профилактики (preventive program) данных используют наборы правил для выявления проблем и выполнения контрольного редактирования входных данных. Программы этого типа повышают качество данных, которые хранятся в оперативной системе, за счет повышения качества первоначально вводимых данных.
Хотя программные продукты для улучшения качества данных могут быть разделены на четыре довольно простых группы, возможности и преимущества продуктов, поставляемых на коммерческой основе, весьма различаются. Выбор конкретного программного продукта по функциональным возможностям, цене и продуктивности применительно к конкретной ситуации следует осуществлять на основе определенных требований и возможностей проекта. Перечень программ повышения качества данных, приведенный в табл. 7.2, далеко не полный и может рассматриваться только в качестве иллюстрации.
Помимо продуктов, поставляемых на коммерческой основе, для удовлетворения требований к качеству данных применительно к конкретной ситуации можно, очевидно, разработать ПО под заказ. Поскольку стоимость разработки и сопровождения заказного ПО довольно велика, а цена коммерческих продуктов относительно невысока, с целью повышения качества данных обычно приобретается готовое коммерческое ПО. В тех случаях, когда организация обладает большим опытом в написании программ извлечения или очистки данных либо такие программы уже имеются в наличии, для выполнения очистки данных рентабельнее использовать заказное ПО.
7.8. Оценка данных, или аудит
Мы рассмотрели выгоды, обеспечиваемые высоким уровнем качества данных, процесс получения качественных данных и программные средства анализа качества данных. В разделе 7.1 мы кратко остановились на том, как открыть программу повышения качества данных. Проблема, которую осталось рассмотреть, связана с характером и глубиной вопросов качества данных применительно к определенному проекту. Лучшим способом количественной оценки подобных проблем в организации является аудит, или оценка данных. Первичная оценка данных имеет целью убедить спонсора в том, каков характер проблемы и насколько она серьезна. Коль скоро проект в области качества информации имеет спонсора, аудит данных призван продемонстрировать ему, на что должен быть направлен проект. Это сводится к обычной проблеме поиска спонсорской поддержки проекта, смысл которого не вполне ясен для того, чтобы сформулировать выгоды при отсутствии финансирования для прояснения смысла проекта. Это вошедшая в поговорку проблема курицы и яйца.
Таблица 7.2. Примеры программ для повышения качества данных
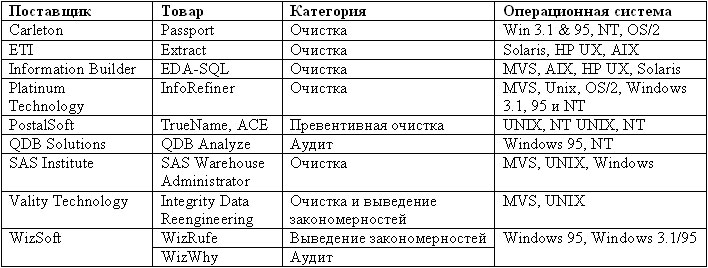
Цель первичного аудита – количественная оценка текущей ситуации в области качества данных. Это способствует выявлению тех областей, в которых возможно улучшить положение дел с качеством данных в организации, а также позволяет начать процесс подготовки к предстоящей формулировке выгод, которые сулит повышение качества данных. Если процесс повышения качества уже выполняется или завершен, аудит данных должен дать оценку достигнутому в этой области прогрессу.
Факторы, имеющие решающее значение для успеха аудита, можно определить следующим образом: нужно начинать с малого, ограничиваться только теми полями данных, которые обещают наибольшую отдачу, и не терять концентрацию. Очень важно, чтобы аудит данных завершился в течение короткого периода времени, для первичного аудита это, скажем, один-два месяца. В ходе аудита данные и метаданные подвержены изменениям, поэтому слишком продолжительный процесс аудита приведет к столь значительным изменениям в данных и метаданных, что поставит под сомнение его результаты. Спонсоры также желают как можно быстрее получить зримые результаты. Важно, чтобы аудит данных не превратился в процесс, подобный попыткам построить корпоративную модель данных, которая "проваливается" из-за своих масштабов и неспособности своевременно предъявить ощутимые результаты.
На рис. 7.1 показана схема потока процесса реализации программы повышения качества данных. К изображенным на этом рисунке областям, которые вовлечены в процесс аудита данных, относятся установление уровня качества определений данных или метаданных, а также уровня качества хранимых данных (им соответствуют квадраты, помеченные цифрами 2 и 3). Невозможно определить, правильно ли используется слово в предложении, не определив темы сочинения. Точно так же невозможно узнать, верно или неверно введен или вычислен экземпляр данных без определения поля данных. Поэтому программа повышения качества данных обязательно должна начинаться с исследования качества метаданных. Только исследовав метаданные, можно приступать к исследованию хранимых данных, чтобы определить их корректность в соответствии с тем, как она определена метаданными.
Что означает понятие "хорошие данные"? Определения данных должны иметь смысл для бизнес-пользователей и соответствовать стандартам моделирования данных, принятым в организации. Хорошее определение данных должно быть понятно бизнес-пользователям и сформулировано с применением языка и сокращений, содержательных с точки зрения бизнес-процессов. Определение должно быть недвусмысленным, полным, ясным и точным. Определение данных также должно содержать любые бизнес-правила, охватывающие использование элементов данных, вместе с правилами, которые управляют целостностью или связями с другими полями данных. В пределах организации должно использоваться только одно определение элемента данных.
Какие еще способы обнаружения ошибок в содержимом данных существуют, помимо использования ПО для выявления проблем с данными? Другими словами, каким образом можно выполнить аудит содержимого данных, обозначенный на рис. 7.1 блоком 3? Для проверки точности хранимых данных можно привлекать людей, факты и события.
Люди, например представители сферы обслуживания клиентов или продавцы, имеют возможность осуществить проверку содержимого данных вместе с клиентом. Например, продавец может уточнить у покупательницы, по-прежнему ли она живет по адресу Колорадо, аллея Адаме, 123. Компания Hewlett-Packard использовала для проверки собранных данных о клиентах технологию телемаркетинга. Еще одна возможность проверки – отправить клиенту вопросник, воспользовавшись услугами почты первого класса. Неверно адресованные отправления будут возвращены, что послужит признаком проблемы с почтовым адресом.
События, например заказ, сделанный клиентом, дают возможность проверить, что адрес, указанный в заказе, совпадает с адресом, который хранится в системе. Некоторые компании уточняют детали заказа с помощью немедленного телефонного звонка клиенту с подтверждением получения заказа. Звонки клиентов с жалобами также позволяют уточнить и исправить данные.
Еще один способ повышения качества данных – проверка любых физических свойств хранимых в базе данных. Например, данные могут отображать факт наличия у товара определенной длины, ширины, высоты и веса. Эти физические размеры можно легко проверить, измерив товар. При этом неплохо задаться вопросом: учитывают ли эти физические размеры упаковку?
После выполнения первичного аудита качества данных можно приступать к реализации программы повышения качества. Для организаций с очень высоким уровнем очистки данных подобная программа может сводиться просто к проведению периодического аудита данных. Организациям, у которых более серьезные проблемы с данными, для устранения проблем может потребоваться реализация более существенной программы. Этим организациям необходимо реализовать полный вариант мероприятий коррекции данных, как показано на рис. 7.1.
Вопросы
7.1. Что касается проблемы качества данных, то уменьшительные имена, с одной стороны, могут вызвать проблемы, а с другой – предоставить больше возможностей. Помимо необходимости знать, что к кому-то нужно обращаться Роберт, а не Боб или Элизабет вместо Лиз, существуют еще такие имена, как Джек и Джон, хотя законное имя может быть Джон, но некто предпочитает, чтобы его называли Джек. Разработайте план, направленный на то, чтобы база данных клиентов точнее и шире отражала личные предпочтения.
7.2. Укажите названия ролей, вовлеченных в процесс формирования и сопровождения информации по качеству данных, и соответствующие этим ролям обязанности.
7.3. Опишите функции программы аудита данных.
7.4. Опишите функции программы очистки данных.
7.5. Опишите функции программы профилактики проблем качества данных.
7.6. Опишите функции программы выведения закономерностей в данных.
7.7. Предположим, магазин рассылает рекламные обращения 50 млн. своих покупателей и 10 % адресов в списке рассылки содержат ошибки, а потому эти рекламные послания не доходят до адресатов. Создание и отправка по почте каждого рекламного проспекта обходится в 79 центов. Кроме того, 10 % клиентов, не получивших почтового обращения, могли бы купить товары, принеся магазину в среднем 1 доллар прибыли. Во что обходятся подобные ошибки в данных?
7.8. Приведите факторы, которые могли бы свидетельствовать в пользу приобретения, а не разработки программных средств очистки данных.
7.9. Опишите различные пути появления ошибок в данных и методов их исправления или предотвращения.
7.10. Сформулируйте, какими качествами должно обладать хорошее определение поля данных.
7.11. Исходя из данных табл. 7.3, попробуйте оценить, за какой оптимальный процент ошибок стоит бороться. Приведите как можно более подробное объяснение своей оценки.
7.12. Какие шаги следует предпринять для открытия программы повышения качества данных?
7.13. Ваша организация в течение пяти лет работала над программой повышения качества метаданных. Вы уверены, что дела с метаданными обстоят в организации блестяще. Какая альтернатива существует в таком случае для шагов, приведенных на рис. 7.1?
7.14. Данные в табл. 7.1 и 7.3 были заданы без каких-либо объяснений. Каким образом могли быть получены эти данные?
Таблица 7.3. Предельные издержки и предельный доход от устранения ошибок в данных
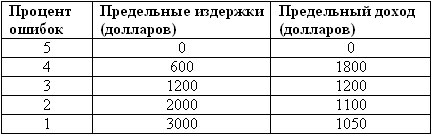
Упражнения
7.1. Анализ характера телефонных соединений представляет собой анализ телефонных звонков, которые осуществляют местные или удаленные клиенты. Этот анализ должен выявить тенденции в телефонных звонках для определения того, выиграют ли клиенты от введения специальных видов услуг или цен. Демографические данные о клиентах обычно получают из внешних источников. Информация собирается с помощью коммутатора, который маршрутизирует вызов. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.2. Сеть, которая соединяет телефонных абонентов, представляет собой очень дорогой и ценный ресурс. Планирование расширения сети – задача весьма ответственная, поскольку может привести к потере дохода, если телефонные услуги не находят спроса, или к повышению издержек, если слишком длинные участки сети проложены в неверном направлении. Сетевая информация фиксируется несколькими системами. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.3. Для того чтобы определить, какие автомобили и аксессуары предпочитают приобретать покупатели из определенных демографических групп, производители и дилеры автомобильной отрасли выполняют анализ тенденций покупательского поведения. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.4. Напомним, что для определения того, какие товары предпочитают приобретать покупатели из определенных демографических групп, магазины могут выполнять анализ тенденций покупательского поведения. Например, магазин электроники может выяснять, какие демографические группы предпочитают покупать те или иные товары. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.5. Компании-производители могут использовать хранилище данных, чтобы следить за тем, насколько точно их поставщики выполняют соглашения. Обычно в соглашении оговариваются, как минимум, сроки поставки и качество товаров. Производители могут делать это, чтобы повысить качество товаров и снизить затраты на хранение слишком больших запасов. Другие технологии, например электронный обмен данными (electronic data interchange – EDI), позволяют компаниям- производителям и их поставщикам обмениваться информацией о заказах и поставках комплектующих в электронном виде. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.6. Финансовые организации могут использовать хранилище данных для анализа рисков, связанных с обслуживанием различных клиентов и с некоторыми другими сценариями. Для определения рисков, связанных с выдачей ссуд, эти хранилища могут использовать демографические данные или данные, отражающие кредитную историю. Это позволяет финансовым учреждениям оценивать риски и управлять ими. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.7. Авиакомпании могут анализировать тенденции, касающиеся поездок своих постоянных пассажиров из различных демографических групп. Эту информацию можно использовать для выявления целевых сегментов наиболее часто путешествующих пассажиров в соответствующих группах на рынке. Демографические данные авиакомпании обычно получают из внешних источников. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.8. Напомним, что авиакомпании могут использовать хранилища данных для отслеживания сезонных колебаний и прогнозирования роста путешествий между определенными пунктами. Эти данные могут также показать количество еды и напитков, потребляемых на различных рейсах. Это может помочь авиакомпании выбрать такой тип самолета и обслуживания питанием, чтобы удовлетворить потребности своих клиентов. Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.9. Учебные заведения могут использовать хранилища данных для анализа тенденций, связанных с записью в определенные группы, успеваемостью студентов и их оценкой профессорско-преподавательского состава. Данные могут загружаться в хранилище в конце каждого учебного периода. Информация о записи в определенные группы поступает из системы регистрации, а данные об успеваемости студентов могут быть загружены из компьютерной системы деканата учебного заведения. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.10. Учреждения здравоохранения могут использовать хранилища данных для отслеживания диагностических кодов (так называемых 1СВ9-кодов) и лечебных процедур, назначаемых в случае соответствующих диагнозов (так называемых СРТ-кодов), а также стоимости этих процедур. Эти данные можно использовать для анализа степени успешности процедур, применяемых при установленном диагнозе, или их стоимости в сравнении с суммой страховой компенсации. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.11. Гостиницы могут анализировать тенденции в отношении проживания своих наиболее частых постояльцев из различных демографических групп. Эту информацию можно использовать для целевых сегментов постоянных клиентов, которым стоит предлагать комплекс услуг на время отдыха. Демографические данные обычно получают из внешних источников. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
7.12. Напомним, что гостиницы могут использовать хранилища данных для отслеживания совокупной ценности пребывания в их заведении наиболее частых постояльцев. Совокупная ценность пребывания представляет собой общую сумму, которую тратит постоялец за время своего проживания, включая оплату номера, ресторана, обслуживания в номере, расходы в магазине подарков и другие эпизодические расходы. Какие возможности для повышения качества данных открываются в этой системе? Какие таблицы и элементы должны быть подвергнуты аудиту в первую очередь? Сформулируйте несколько примеров хороших определений данных, используя модель данных для этого проекта.
* * *