Первоисточник статьи на английском языке доступен на www.tdan.com
1.0 Введение
Назначение этого документа – представить и обсудить процессы загрузки Data Vault™. Это заявленный на патент подход к моделированию корпоративных хранилищ данных (прим. переводчика: статья была написана в 2001 году, в предоставлении патента было отказано в январе 2005; сейчас архитектура Data Vault – общедоступна – FREE and PUBLIC DOMAIN), это – эволюционный подход к решению проблем, связанных с частыми и огромными по объему загрузками хранилищ данных. Этот документ, предназначен для аудитории, состоящей из заинтересованных в реализации архитектуры и процессов, загружающих данные в соответствующие сущности. Мы также обсуждаем шаблоны с точки зрения 5-го уровня SEI/CMM – повторяемость, надежность и измеримость результатов. В этой статье рассмотрены следующие темы:
- Загрузка сущностей Хабов (Hub)
- Загрузка сущностей Связей (Link)
- Загрузка сущностей Спутников (Satellites)
- Выводы и заключение
Прочитав это документ, Вы можете узнать:
- Как разработать единообразные и повторяемые процессы ETL.
- Лучшие методы (Best Practices) для информации различных типов сущностей
- Обзор парадигмы загрузки для Data Vault
Этот документ рассматривает эти процессы с точки зрения повторяемости и последовательности подхода проектирования. Здесь представлены только концепции загрузки данных, не включающие ни одного фактического фрагмента кода, необходимого для достижения этих результатов. В зависимости от выбранного механизма загрузки код или дизайн могут несколько отличаться. Эта статья предлагает лучшие методы в стратегической и тактической (загрузка в режиме близком к реальному времени) перспективе.
Проектируя Data Vault, я рассмотрел лучшие методы для построения масштабируемых и повторяемых хранилищ – включая обработку загрузки и обработку запросов. Чтобы удовлетворить этим потребностям, я спроектировал методологию реализации, известную как Матричная Методология (The Matrix Methodology™).
2.0 Обзор Матричной Методологии (Matrix Methodology)
Матричная Методология (Matrix Methodology, ТММ) определяет повторяемую и согласованную архитектуру для загрузки, обработки и извлечения данных из корпоративного хранилища данных. «Сердцем» методологии является выбор Data Vault в качестве архитектуры хранилища данных предприятия. Так что остается лишь поинтересоваться, что именно представляет собой методология ТММ? Что она делает? Почему ТММ так же важна, как и Data Vault? Мы коротко исследуем эти вопросы – для начала нижеследующее изображение показывает, из чего состоит Матричная Методология:
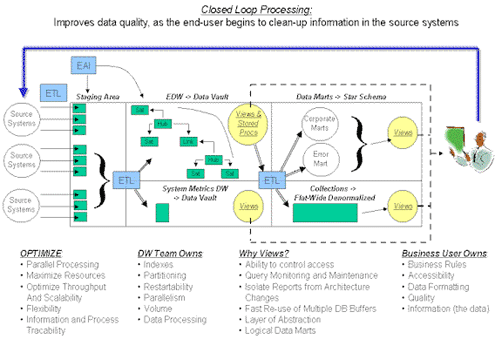
Рисунок 1-1 Матричная Методология (The Matrix Methodology)
На рисунке изображены компоненты ТММ. EAI указывает на тактическое процессы загрузка непосредственно в Data Vault (EDW). TMM определяет слои обработки и лучшие методы со многими шаблонами и проектами, которые легко сопровождаются. Эти шаблоны доступны для продажи.
Почему это называется «Матричной методологией»?
Это – матрица решений. Деление этой матрицы компонентами вертикально и горизонтально в соответствии масштабу (scope) резко уменьшает риск неудачи, способствует повторному использованию и быстро поставляет результаты. Data Vault – это только один компонент, который, случается, становится главным компонентом и сердцем архитектуры. Горизонтальная линия, проходящая через компоненты, обеспечивает нам реализацию «снизу вверх» – осуществление только того, что согласовано с конечным пользователем для текущего релиза.
Автоматическая обработка помещает данные прямо в руки пользователя; а также возвращает ответственность за качество информации назад в руки пользователя. Мы используем технику, названную Витриной Ошибок (Error Mart) для поставки данных, которые не соответствуют требованиям. Но достаточно про TMM – не стесняйтесь, пишите мне по электронной почте, если у вас возникнут вопросы, касающиеся методологии. Дело здесь заключается в следующей диаграмме: фазы загрузки Data Vault.
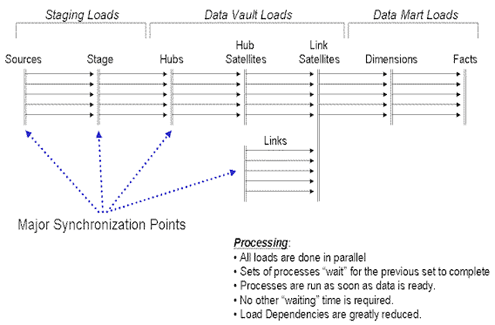
Рисунок 1-2 Параллельные процессы загрузки в Data Vault
Диаграмма показывает последовательность загрузки в Data Vault. Мы обсудим шаблоны для каждого конкретного этапа загрузки Data Vault. Мы не предоставим шаблоны ни для загрузки буферной области (staging area), ни витрин данных.
Что делает загрузку Data Vault особенной?
Data Vault основано на последовательной вставке данных. Информация в Data Vault должна оставаться последовательной – данные только вставляются, не удаляется и не обновляется (кроме случаев, связанных с проблемами подачи данных). Другими словами, если набор данных не был откачен, или не было обнаружено, что набор данных ошибочен, то он не будет ни удален, ни обновлен. Следующие понятия учитываются, когда создаются шаблоны для загрузки:
- Требования к объемам (Volume Requirements)
- Требования к задержке (Latency Requirements)
- Повторяемость, воспроизводимость (Repeatability)
- Последовательность – Единообразие для исторической, текущей и начальной загрузки.
- Надежность (Reliability).
- Возможность перезапуска (Restartability) – не более чем простая «кнопка» повторного запуска, для восстановления загрузки с места, где она была прервана.
Как уже отмечалось, Data Vault является архитектурой моделирования для корпоративных хранилищ данных, и поэтому становится для предприятия системой документально зарегистрированных данных. Система документально зарегистрированных данных должна быть надежной и согласованной во всех аспектах и методах.
Имея с одной стороны источники, производящие огромные объемы данных и потребность соблюдать законы и соглашения с другой – в таких условиях важно создать надежные механизмы загрузки. Наши механизмы загрузки должны быть надежными настолько насколько это возможно. Конечно, есть и другие важные моменты, такие как отслеживание дат загрузки и записей источников, которые в настоящем документе не рассматриваются. Типичные лучшие практики определяют эти пункты, касающиеся выгрузки информации (загрузки в промежуточную/буферную область).
Итак, давайте рассмотрим фактические процессы загрузки.
2.1 Загрузка сущностей Хабов
В сущность Хаб делаются запись только при первом появлении бизнес ключа в системе системы Data Vault. В Хабы не записывают последующие загрузки или любые изменения тех же самых данных. Чтобы загрузить хаб, мы должны сначала проверить, была ли запись уже загружена (уже существует). Это будет учитывать как ранее прервавшийся процесс загрузки, так и дублирование информацию в пределах одного и того же механизма загрузки. Захват измененных данных (Change Data Capture, CDC) в исходной системе хорошо помогает, пока процесс загрузки в хранилище не прерывается. На этом этапе нам требуется стандартизированный механизм для того, чтобы обнаружить изменения, происходящие при обработке хаба. Ниже показана последовательность процессов для загрузки хаба:
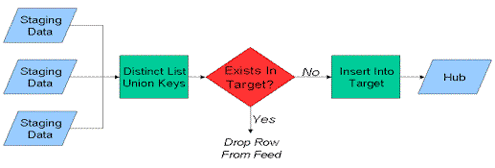
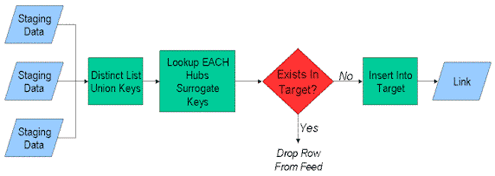
Рисунок 2-1 Загрузка сущности Хаб
Загрузка Хабов довольно проста. При загрузке Хабов необходимо помнить несколько вещей. Необходимо учитывать следующее:
- Все бизнес ключи Хабов должны быть уникальными, и находиться в соотношении один к одному с суррогатами.
- Ключи Хаба не зависят от времени
- Ключи Хабов не могут дублироваться
- Ключи Хаба определены в тех же самых семантических слоях
Загрузка хаба состоит, во-первых, из идентификации основной «мастер» системы – системы, где по мнению бизнеса фактически генерируется большинство ключей; конечно это предположение должно быть проверено на реальных наборах данных, прибывающих из этой системы. Как только основная система идентифицирована, то первоначально извлекают данные из нее. Загружается уникальный список ключей, не существующих в преемнике данных, и во время загрузки им обеспечивается соответствующий суррогатный ключ. Остальные системы сортируются с точки зрения важности. Из второй системы (наиболее вероятно, генерирующей ключи, даже если бизнес заявляет, что эта система никогда их не производит), загружают данные подобным образом.
Этот процесс повторяется для каждой исходной системы, которая содержит ключевые поля хаба. Это понятия «содержит ключ хаба» никак не поддерживается фактическим дизайном исходный системы – другими словами, поле, используемое для ключей хаба, может быть, а может и не быть внешним ключ в исходной системе. Мы констатируем тот факт, что ключ действительно существует, и поэтому он должен быть помещены в Хаб. Наконец, существуют информационные компоненты, у которых нет никакого ключа; например, таблица содержит основную информацию о продукте, и является вторичным источником для номера или адреса клиента; в нашем случае номер клиента является пустым, а адрес клиента заполнен. Что мы делаем? Мы заполняем номер клиента пустышкой, поместив его к строке хаба, называемой строкой с нулевым ключом или UNKNOWN), так, чтобы данные об адресе клиента не были потеряны во время загрузки Спутников.
Дубликаты в Хабах вызовут много других проблем, начиная от проблем SQL запросов до проблем дополнительного моделирования. Не рекомендуется загружать дубликаты в ключевые поля Хаба. Хорошо, а что относительно «плохих данных»? Существует конкретный пример неправильных данных. Другими словами, в исходной системе есть номер счета клиента, но эта система была «продана» в разные штаты, и поэтому есть дубликаты номеров счетов (для различных клиентов). Как мы загрузим эти данные?
Одна из идей заключается в том, чтобы фиксировать источник в составном бизнес ключе – это типичное решение, обычно предлагаемое для обеспечения уникальности, но на горизонте был другой подход: добавить к номеру счета клиента «код штата» или другую идентифицирующую часть данных, чтобы синтезировать уникальность. Это будет работать, но только ограниченное время. В конечном счете, если вторичный или третичный ключ, выбранный для добавления к бизнес ключу, начнет обладать квалифицирующими или идентифицирующие свойствами, тогда он должен будет выделен в свой собственный Хаб.
Другими словами, мы можем временно исправить положение, используя «Код Штата», но если мы должны будем начать захватывать информацию о коде штата, мы будем вынуждены создать для этого отдельный Хаб. Основные правила здесь следующие: плохо идентифицированные входные элементы вызывают архитектурные разрывы, приводящие к разрушению дизайна Data Vault. Это обычно означает, что у системы источника есть некоторые проблемы в проектировании, уходящие глубже, чем только набор данных.
Когда мы смотрим на реальные процессы загрузки, все Хабы могут и должны быть загружены параллельно на первом шаге. Таким образом, мы можем создать хорошо масштабируемую архитектуру – больше данных, больше Хабов, более простая загрузка обрабатывающая все параллельно. Мы можем также инвестировать в аппаратные средства, и тем самым поддержать проект, когда увеличится нагрузка и потребуются новые аппаратные средства. Это для пакетно-ориентированного решения, когда данные готовы, загрузите их.
2.2 Загрузка сущностей Связей
Таблицы Связи без суррогатных ключей загружаются точно таким же образом, как и Хабы. Однако, так как сегодня большинство корпоративных хранилищ данных использует суррогатные ключи, мы укажем дополнительный шаг в процессе загрузки, чтобы найти соответствующие строки Хабов.
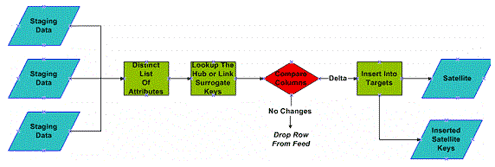
В этом контексте загрузка таблиц Связи выполняется следующим образом (имейте в виду, что эта презентация последовательности загрузки основана на пуританском подходе). Во-первых, мы формулируем список всех уникальных бизнес ключей, которые составляют связанные данные (relationship data) для связи. Затем, мы находим или определяем местонахождение каждого соответствующего им суррогатного ключа в Хабе. Наконец, мы проверяем, существуют ли они в целевой таблице, если нет, то вставляем запись с новым суррогатным ключом Связи, если существуют, то запись выбывает из обработки.
Дубликаты в таблицах Связи обычно означают плохое определение гранулярности, или неправильное смоделированную сущность Хаб. В этом случае «дубликат» означает дублирование бизнес ключей, а не дублирование суррогатов, конечно же. Проблема, как правило – гранулярность. Если процессы не могут найти старую спутниковую запись для датирования окончания (притом, что она существует), то это недостаток гранулярности модели таблицы связи. В таком случае таблица Связи должна быть перепроектирована, чтобы соответствовать степени детализации
Загрузка таблицы Связи успешны, когда ВСЕ отношения между бизнес ключами были записаны. Если есть пропавшие бизнес ключи, тогда подобно Хабам, мы загружаем «нулевые» ключи и связываем их отношениями с «unknown» строками Хабов. Это позволяет продолжать загружать данные без поломок. Захват всех отношений, даже неполноценных, предоставляет бизнес пользователям все возможности аудиторского исследования (ИТ и Бизнес могут проследить происхождение информацию до исходных систем). Все загрузки Связей можно также запускать параллельно. Фактически, если доступно достаточно аппаратных средств, рекомендуется загружать Связи одновременно с загрузкой Спутников Хабов. Это позволяет достичь максимальной пропускной способности.
2.3 Загрузка сущностей Спутников
Загрузка Спутников является легкой частью. Датирование окончания действия записей Спутника иногда требует немного больше работы. Конечно это - краткий высокоуровневый обзор процесса загрузки. Полное изложение информации о процессах загрузки будет в моей готовящейся книги, части которой Вы можете найти на www. DanLinstedt.com. Для загрузки Спутников используется следующая архитектура:
Этот рисунок представляет загрузку Спутника. В этой загрузке мы, во-первых, создаем список уникальных атрибутов. Это необходимо, чтобы не загружать «задвоенные строки атрибутов» в целевой Спутник. Все строки, которых есть в источниках, должны быть учтены и загружены в приемник данных. Это означает использовать заданные по умолчанию наборы данных для некоторых колонок, поэтому мы советуем задать эти значения как часть процесса. Однако значения, заданные по умолчанию, не используются для численных данных, они остаются со значением NULL. Конечно, высшей ценностью является оставить все поля NULL, если они прибывают в этом формате, однако это делает запросы и сравнения трудными.
Затем, мы ищем ключ любо Хаба либо родительский ключ Связи так, чтобы строка Спутника могла быть связана надлежащим образом. Если родительский ключ не существует – у нас механическая ошибка в наших процессах загрузки Хабов или Связей – в этом месте необходимо сгенерировать оповещение и остановить процесс загрузки. Как только ошибка устранена, это должно остаться неизменным на долгое время. Затем, мы сравниваем прибывшие данные в колонках с текущим состоянием данных Спутника. Это делается для гарантии того, что мы НЕ загружаем дубликаты данных. Мы не хотим проблемы взрыва данных в Спутниках, поэтому здесь заставляем Спутники соответствовать скорости изменения и типу информации.
Если элементы строки содержат измененные значения (дельту), или просто еще не существуют в таблице приемнике, эта строка вставляется. Есть вспомогательная таблица, поддерживаемая в буферной области (staging area). При каждой загрузки эта таблица очищается и перезагружается только первичными ключами записей спутника, который вставлены во время обработки. Это облегчает получение первичных ключей Спутника, и завершить процесс, датирующий окончания действия строк, не просматривая при этом весь набор данных в Спутнике, чтобы узнать, что новое, а что нет. Архитектура процесса датирующего окончания действия может выглядеть подобным образом:
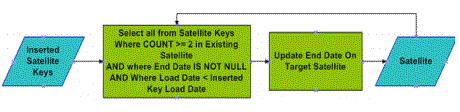
В этом процессе загрузки, записи Спутника, которые не были датированы датой окончания, получат значения дат окончания. Этот специфический процесс полностью перезапускаемый и масштабируемый. Только в необходимых строках Спутника будет проставлена дата окончания. Если вставленные строки были уже обновлены, то они не будут датированы снова. Датирование датами окончания строк Спутника важно, чтобы знать какие данные являются активными. Все процессы разработаны таким образом, чтобы быть по своей природе повторяемыми, последовательными, масштабируемыми и перезапускаемыми. Вместе с тем, нужно учитывать загрузка данных в режиме близком к реальному времени немного меняет дизайн процессов загрузки.
2.4 Загрузка в реальном времени (Real-Time Loading, EAI)
Обычно в системе реального времени транзакции содержат: Бизнес ключи Хаба, отношения (непосредственно сделка), и данные, описывающие транзакцию (или информация в Спутнике Связи). Кроме того, в таких системах данные поступают слишком быстро и слишком «яростные», чтобы тратить время, необходимое, чтоб поместить их в буферную область, попытаться очистить и подготовить к загрузке в хранилище данных. Минута, потраченная на очистку или объединение данных, – это пришедшие в негодность или «умершие» данные, так как транзакция уже была или обновлена, или удалена. В любом случае, захват транзакционных данных в буферную область любого типа является трудным и почти невозможным без некоторого допустимого времени задержки.
Примером транзакции могло быть изъятие (снятие денег со счета) в банкомате, где счет был открыт в 8:00, а изъятие было сделано в 9:00. Транзакция, которая поступит в нашу систему, указывает только номер счета, общую изъятую сумма, дату и время осуществления, и вероятно филиал. Также могло быть указана общее сумма на счете, доступная для снятия. Наиболее вероятно эта транзакция не содержит информации об имени клиента, адресе, или кредитном рейтинге. Эти детали поступят ночным рейсом в главный банковский компьютер, вероятно поздно вечером. Итак, мы должны сохранить номер счета в Хабе, номер клиента в Хабе, а снятие клиентом со счета в таблице Связи, чтобы сделать ассоциацию. Если у нас есть номер филиала, где произошло снятие, то его можно было бы зарегистрировать в таблице Связи как местоположение. Наконец, построить Спутник на связи с общей суммой счета, датой, временем и снятой суммой.
В среде реального времени, ключи будут вытянуты из транзакции, Хаб будет загружен на лету, и таблицы связи заполнены в то же самое время. Наконец наиболее вероятно, что во время загрузки в реальном времени, Спутниковая информация для Связи (детали транзакции) также будет доступна, таким образом, она будет загружена либо одновременно или почти одновременно с родительской таблицей Связи.
Среда реального времени изменяет требования ко времени ожидания / задержки. Обычно там меньший объем для обработки, но и более короткий промежуток времени на загрузку с момента поступления. Если бремя ложится на процессы загрузки, то меньше шансов построить систему реального времени. Другими словами, тяжелая дополнительная работа по обеспечению качества данных, очистка, сопоставление, очистка, и т.д... все вызывает замедление и увеличение времени ожидания, что недопустимо во время загрузки данных в режиме реального времени. В качестве заключительного примера, возьмите любую транзакцию, поступающую в реальном времени (5-секундные обновления). Мы получаем транзакцию, которая «говорит»: вставьте меня, я новая. Наши правила запрещают данным попадать в хранилище – таким образом, процесс загрузки строки терпит неудачу и она помещается в плоский файл, затем мы получаем оповещение о необходимости исправления ошибки, прежде чем эти данные смогут попасть в хранилище.
Если нам требуются 5 минут, чтобы исправить данные и 5 минут, чтобы перезагрузить их, то к тому времени, когда мы исправили и перезарядили их, мы получили дополнительные данные транзакциях, которые за это время были либо обновлены, либо удалены. Мы опять отстаем. Архитектура загрузки, спроектированная подобным образом, не будет работать в режиме реального времени. К сожалению, выбранные модели данных убеждают нас в этом мнении и этих парадигмах. Использование Data Vault поможет предотвратить некоторые из этих катастрофических результатов в ходе цикла загрузки.
3.0 Заключение
Таким образом, эта статья является вводным обзором процессов загрузки для всех основных типов таблиц. Эта архитектура загрузки основана на строгом подходе к проектированию Data Vault. При создании, конечно, будут отклонения. Однако 80 % или больше проектов, как созданных с помощью ETL-инструментов, типа Informatica, Ab-Initio илиr Ascential, так и написанный на SQL в базе данных, будут следовать тем же самым стандартным парадигмам. Не трогайте и не изменяйте данные по пути в хранилище Data Vault, манипулируйте ими в соответствии с бизнес-правилами вне хранилища – в витринах данных.
Кроме того, если должна быть некоторая интерпретация, некоторый слой свернутых (roll-up) или агрегированных данных, то создайте иерархическую таблицу Связи и проставьте значения в поле «источник данных» равное «SYSGEN» или некоторому подобному значению. Это позволит держать порожденные / сгенерированные данные отдельно от данных исходных систем, и сохранит отслеживаемость. В настоящее время есть несколько проектов Data Vault в стадии создания, и одна крупная законченная реализация. Следующая серия статей будет исследовать некоторые методы запросов, необходимых для получения данных из структуры Data Vault.