Первоисточник статьи на английском языке доступен на www.tdan.com
Аннотация
Назначение этого документа – представить и обсудить заявленную на патент технологию под названием Data Vault™ (прим. переводчика: статья была написана в 2001 году, в предоставлении патента было отказано в январе 2005; сейчас архитектура Data Vault – общедоступна – FREE and PUBLIC DOMAIN). Data Vault™ – новый этап эволюции моделирования данных для хранилищ данных масштаба предприятия. Это – четвертая статья в ряду публикаций о Data Vault. Эта статья исследует пример Data Vault, приведенный в 3-ей статье Серии, расширяет понятия Связывания, Спутников добавленных к Связям и дополняет описание методов соединений (join techniques). Таблицы Связи – экземпляры отношений «многие ко многим», возникающие в бизнесе и в логических моделях. Спутники, отходящие от таблиц Связей, представляют информацию об изменении соответствующего контекста. Первая статья серии обсуждала Хабы, как сингулярные конечные ключи бизнеса, а Связи как некий составной ключ.
В этой статье мы также рассмотрим «проблему связей и отношений». Эти проблемы представлены очень кратко, наряду с некоторыми потенциальными решениями. Движки СУБД имеют непосредственное отношение к проблемам связей и соединений, их внутренний алгоритм не был настроен на обработку огромных объемов данных, с которыми в настоящее время имеют дело предприятия. Запросы в отношении этих структур представлены здесь, но подробно обсуждаться не будут до будущей статьи.
Имейте в виду, что содержит этот документ. Следующая статья серии будет обсуждать такие темы, как: вставка, обновление, удаление, обработка фактов, агрегатов, загрузка в режиме близком к реальному времени и пакетные загрузки. Рекомендуется, чтобы Вы были знакомы с концепцией Data Vault и прочитали предыдущие публикации на www.tdan.com или у нас на сайте.
1.0 Введение
Назначение этого документа – представить и обсудить заявленную на патент технологию под названием Data Vault™ (прим. переводчика: статья была написана в 2001 году, в предоставлении патента было отказано в январе 2005; сейчас архитектура Data Vault – общедоступна – FREE and PUBLIC DOMAIN). Data Vault™ – новый этап эволюции моделирования данных для хранилищ данных масштаба предприятия. Целевая аудитория этой статьи: проектировщики данных, желающие построить модель Data Vault, или специалисты в области хранилищ данных и BI, интересующиеся запросами к Data Vault. Здесь мы сосредотачиваемся исключительно на таблицах Связей и Спутниках, являющихся дочерними таблицами Связей, наряду с некоторыми методами запросов данных из Связей. Мы также обсуждаем проблемы, связанные со степенью детализации таблиц Связи, добавления новые Хабов и их влияния на масштабируемость. В этой статье рассмотрены следующие темы:
- Сущность Связь (Link).
- Спутники для сущности Связь.
- Факты и агрегаты, хранимые в структурах Связей.
- Изменение степени детализации в сущностях Связях.
- Операции соединения (join), использующие сущности Связи.
- Выводы и заключение.
Прочитав это документ, Вы можете узнать:
- Как моделировать различные составные ключи (сущности Связи).
- Как размещать факты в Спутниках.
- Как изменение степени детализации воздействуют на архитектуру.
- Что представляет собой сущность Связь.
- Некоторые из проблем, с которыми сталкиваются сущности Связи
В архитектуре Data Vault составные ключи всегда представляют собой отношения между двумя типами бизнес ключей. Эти ключи «расквартированы» по отдельным Хабам, а для того чтобы представить взаимоотношения между ними, архитектура обеспечивает табличную структуру, реализующую связь «многие ко многим». Помните, все это предназначено для хранилищ данных, а не для нормализованных OLTP систем – поэтому, архитектура была перепроектирована, чтобы удовлетворить эти потребности.
Единственное исключение в этом правиле о составных ключах – дата загрузки, которая используется как часть первичного ключа Спутников для фиксирования времени загрузки. Сущность Время (календарь) стоит особняком в модели Data Vault как один из нескольких типов таблиц, не связанных между собой. Если бы мы должны были связать сущность Время (календарь) с каждым Спутником, то модель была бы слишком сложной для чтения.
Под этим обликом архитектура обеспечивает таблицу «многие ко многим», которая играет важную роль в: гибкости, расширяемости, возможности изменений, и ассоциации между бизнес ключами. Сущность Связь может быть самым мощной сущностью в пределах архитектуры. Конечно, сущность Связь добавляет сложности на уровне движков СУБД, связанные с операциями соединения. Это может вызвать общие проблемы с производительностью хранилища данных – но не из-за архитектуры, а из-за проблем на уровне движка СУБД.
2.0 Сущность Связь
Понять сущность Связь (таблица Связь (Link)) значит понять природу взаимоотношений внутри бизнеса. Например, когда человек бизнеса заявляет: «вот номер счета-фактуры», большинство вовлеченных в этот бизнес знают, что это означает. Конечно интерпретации того, что счет-фактура действительно означает для разных групп, может отличаться – поэтому определение метаданных должно проводиться по всей компании. Однако, когда то же самое лицо заявляет: «этот счет-фактура выписан клиенту X», то этим уже установлены отношения между заказчиком и счетом-фактурой.
И клиент, и счет-фактура – это отдельные сущности. Иными словами, счет-фактура не всегда требует данных о клиенте (счета-фактуры могут быть внутренними), а клиент может иметь контакты только с маркетингом и, возможно, не иметь ни одного выставленного ему счета. Общее деловое чутье говорит нам, что необходимо связать счет, по крайней мере, с одним клиентом (под клиентом, может пониматься корпорация, индивидуальное лицо и т.п.).
Существует другая вложенная тема к этим выражениям: реальное время, предприятие с нулевой задержкой, близко к реальному времени, по требованию. Назовите, что будет у вас? Архитектуры моделей данных сегодня (за исключением Data Vault) зависят от наборов данных и времени прохождения данных через обрабатывающие системы, что делает невозможным осуществлять синхронизацию данных в режиме близком к реальному времени. Data Vault, частично из-за таблицы Связи, частично из-за того, как структурированы Хабы, позволяет практически в реальном времени питать данные «позднего связывания» («late-bind» data) или синхронизировать данные при их прибытии. Конечно, это является предметом метаданных, и я отвлекся – так давайте вернемся обратно на уровень выше, и сосредоточим внимание на взаимосвязях между элементами.
Определение, которое приводится в 1-ой статье Серии выглядит следующим образом: «Связь представляет собой отношения или транзакции между двумя или более бизнес-компонентами (двумя или более бизнес-ключами)». Сущность Связь может выглядеть следующим образом:
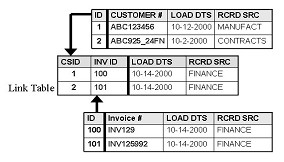
Рисунок 2-1. Связь Клиента и Счет-Фактуры
Здесь показано только два слоя детальный данных: клиент со счетами-фактурами. Чтобы добавить другие детальные данные, добавьте другие Хабы или другие Связи. Приведенное выше изображение показывает, что клиент с идентификатором 1 связан со счетом 100, а клиент с идентификатором 2 связан со счетом 101. Конечно, верхняя и нижняя таблица – Customer Hub и Invoice Hub соответственно.
А что относительно отношений «один к одному», «один ко многим» или «многие к одному»?
Мы пока не рассматриваем управление процессами загрузки, наполняющими структуры данных. Есть несколько важных причин, почему мы реализуем структуру Связей независимо от типа отношений:
- Будущая расширяемость (extensibility) – мы можем легко добавлять Хабы c дополнительными Связями в наши существующие модели хранилищ данных, не нарушая существующую историю. Это важно для успешного развития модели в будущем. Особенно сегодня, когда требования бизнеса быстро меняются – информационные системы и модели данных должны быть в состоянии идти в ногу. В будущем эта архитектура может играть роль на физическом уровне динамически расширяемых моделей данных.
- Изменение бизнес правил – сегодня правило может быть «один к одному», в будущем, бизнес может продиктовать, что на самом деле, один клиент может быть связан с более чем с одним счетом-фактурой, или, возможно, один счет-фактура может быть направлен нескольким клиентам. Когда бизнес меняется, эта структура оставляет модель понятной и позволяет сохранить историю, в то время как новые правила начинают применяться.
- Неуместные (Misplaced) Данные – Слишком часто в существующих архитектурных моделях есть данные, ассоциируемые с таблицами, имеющими составные ключи, но не подходящие этим таблицам. В этой архитектуре моделирования становится проще обнаружить ошибки моделирования и исправить их, иными словами поставить данные в то место, которому они принадлежат, непосредственно с соответствующим ключом.
- Контроль Степени детализации – повсеместное поддержание степени детализации информации очень важно. Удостоверьтесь, что информация или элементы данных размещаются в соответствии их назначению и смыслу, а также, что агрегация контролируется степенью детализации ключей. Добавление еще одного ключа к сущности Связь очень похоже на добавление еще одного измерения к таблице фактов. Это может изменить степень детализации Спутников, связанных со Связью. Для таблицы Связи, не имеющей Спутников, вносить изменения очень легко.
Зачем сразу создавать таблицы Связи?
Частично этот вопрос был рассмотрен в 1-ой статье серии. Важно признать, что объекты существуют в нашем физическом мире без приписывания к другим объектам. Автомобили существуют без водителей, бутылки содовой существуют без потребителей, брюки существуют без владельцев. Эти элементы снабжены ярлыками, пронумерованы, и некоторым способом идентифицированы. Когда человек становится потребителем, владельцем или пользователем, то он становится связанным с этими объектами. Это имеет жизненно-важное значение для повышения уровня понимания информации, имеющейся в нашем распоряжении. Без ассоциации информации у нас есть большая проблема распознавания паттернов и причин существования этих паттернов.
Ассоциации могут быть извлечены из первичных и внешних ключей, но почему разделяют их на таблицы связей?
По большей части бизнес заинтересован не только в ассоциациях, но и в паттернах (моделях) ассоциаций и в ориентирование в этих ассоциациях . Отделяя ассоциативные данные, мы можем начать применять логические механизмы (inference engines) к этим паттернам, и узнать новые факты, возможно, упущенные нами ранее. Основная причина заключается в гибкости. Ассоциации изменяются с течением времени. Как только я потребляю бутылку содовой, я избавляюсь от бутылки, отправляя ее на переработку (утилизацию) – теперь переработчик является владельцем бутылки, а не я. Если история этих отношений может быть отслежена, то в будущем отношения могут регулироваться через различные методы воздействия. Это широко известно, как использование интеллектуального анализа (data mining), для нахождения умозаключений и ассоциативных паттернов, сегментации и детерминированных паттернов, скрытых в данных, которые мы могли бы пропустить и не найти, если бы не извлекали.
Эти ассоциативные паттерны, однажды помещенные в таблицу Связи, легче обнаружить, в будущем легче произвести гибкие архитектурные изменения модели данных, и исследовательские отношения могут быть созданы, измерены и удалены по желанию (или автоматически).
2.1 Спутники для сущностей Связь
Что по поводу дублирования ключей во время процесса загрузки?
Следующая проблема, с которой мы можем столкнуться (справедливо для всех стилей моделирования конечных дат), касается загрузки дубликатов в течение одной потоковой или пакетной загрузки (batch load). Дубликаты (по ключу, но с разным контекстом строки) прибывают в одну и ту же долю секунды из-за высокой скорости процессов массовых загрузок (bulk-loading processes).
Повторяющиеся ключи могут когда-либо появиться только в таблицах Спутник и PIT. Повторяющихся ключей никогда не должно быть в Хабе или Связе. Эти две структуры должны содержать одно и только одно значение того суррогатного и бизнес-ключа, которого они представляют. Эта проблема относится к Спутнику и к PIT таблице, являющейся производной от Спутника и наследующей аналогичные проблемы. Проблематичные строки могут выглядеть следующим образом:
SOURCE:

Где строка 1 – это первая загруженная из системы-источника, а строка 2 – это обновление в системе-источнике. В этом случае они обе должны вставляться в Спутник. Для этого:
- Добавьте инкрементную колонку – это добавит данные и ширину таблицы
- Добавьте секунды к временной отметке (time stamp) – требует сложной логики управления, изменяет процесс выставления временных отметок (time stamping)
- Разделите строки на два обрабатываемых набора – один для вставок (оригинальных строк), один для сравнений при вставке/обновлении.
- Предварительно сгенерируйте дату загрузки в буферной (staging) области; добавьте одну секунду, или одну минуту к информации, чтобы позволить попасть в целевую таблицу.
Все это – потенциальные решения. Единственным решением, которое, работает часто и согласованно для режима близкого к реальному времени, является решение 1. Альтернативные решения в настоящее время исследуются и будут обсуждены подробно на www.danlinstedt.com (домашняя страница Data Vault). Если у Вас в настоящее время строится стратегическое хранилище данных (значение времени ожидания данных – не проблема), то предварительная обработка даты загрузки – наилучшее решение. После того как данные загружены в буферную (staging) область, они могут быть секционированы (partitioned), проверенны и обновлены параллельным способом. Что работает в наших интересах это то, что упомянутый выше случай составляет обычно меньше чем 10 % от всего объема данных. Это помогает уменьшить работу по обновлению, и повысить производительность.
Если строится тактическое (активное/близкое к реальному времени) хранилище данных, то должен быть построен более сложный процесс проверки транзакций – реальный вопрос теперь выглядит так: почему мы получаем две одинаковые строки в течение одной и той же миллисекунды? Если это система практически реального времени, это можно рассматривать как продублировавшиеся операции, а буквально вставить только один раз – и нужно послать сообщение администратору, оповещающее его о том, что возможно есть проблемы в обработке строк в исходной системе. В противном случае, эти транзакции должны быть на «расстоянии», по крайней мере (если не больше), в одну секунду друг от друга.
Спутники функционируют как исторический склад для всей истории. Спутники, связанные с сущностью Связь, представляют историю отношений, связанных композитным ключом. Дополнительное обсуждение Спутников будет в последствии.
2.2 Факты и агрегаты в таблицах Связях
Один из вопросов, который часто задают – возможность обрабатывать агрегированные значения или заранее рассчитывать агрегаты в Data Vault. Ответы, по меньшей мере, интересны. Есть две теории: 1) о том, что новый Спутник может быть присоединен как потомок к таблице Связи. Этот спутник будет содержать агрегированные данные. И, конечно, 2) о том, что в Data Vault будет построен новый уровень (layer) с более высокой степенью детализации. Похоже, как будто, 2-ой вариант более популярный, поскольку позволяет дополнительную денормализацию некоторых объектов структуры данных (позволяющую Связям больше походить на безфактовую таблицу фактов (factless-fact) с дополнительными ключами) и Спутник выглядит как история агрегаций…
Пожалуйста, не путайте это со снежинко-образной схемы. Это не так. Во-первых, таблица связи будет содержать суррогатные ключи, которые никогда не меняются (как и Спутник), во-вторых, спутник может содержать историю агрегированных фактов – в зависимости от того, как таблица фактов была сконструирована, могут или не могут быть доступны.
Эта концепция развивается, и методу номер 2 в настоящее время отдают предпочтение реализуя хранилища в 1 ТБ и больше. Это подводит нас к обсуждению степени детализации.
2.3 Изменение степени детализации в таблицах Связи
Степень детализации (гранулярность) – это огромный вопрос, связанный с витринами данных. Во многих случаях от хранения детальных данных отказываются по причине чрезмерных объемов данных или простоты запрашиваемых фактов. Существует неправильное представление, что витрины данных могут быть легко скомпонованы заново из фактов уровня агрегации (aggregate level). Это далеко от истины. Что делать, если какой-то агрегированный факт считался неправильно в течение последних 2 лет, и детальные данные потеряны или не хранились? Становится непреодолимой задачей – восстановление не только части агрегатных значений, о которых идет речь, но и всех остальных агрегатов, которые зависят от неправильно посчитанного.
Что относительно OLTP в хранилище (3-ья нормальная форма)? В этом случае возникают другие проблемы. Основным виновником является проблема каскадирования первичных ключей, что, в свою очередь причина проблем масштабируемости и гибкости. Это делает почти невозможным включить агрегирование в качестве опции в 3NF модель и точно учесть и определить факты, которые могут в ней содержаться. Data Vault имеет свою долю проблем (наподобие сейчас описанных), однако очевидно, что Data Vault может работать с изменениями степени детализации.
Где могут встретиться проблемы?
Одно из мест и определенно, единственное место – таблица Связи. Все изменения степени детализации направлены на Связи и любые другие Связи, которые соединены вместе (Связь со Связью). Каждый раз как происходит любое добавление или удаление первичного ключа из таблицы Связи, определение степени детализации Спутников изменяется. Каждый раз, когда структура ключа (композитного ключа) меняется, таблица Связи представляет другой набор информации. Однако есть одна очень важная разница между Data Vault, 3-ей нормальной формой и схемой Звезда: таблица Связь в Data Vault не меняет своего первичного ключа, особенно, если используется суррогат в качестве первичный ключа таблицы Связь.
Что означает изменение степени детализации в сущности Связь?
Это меняет определение того, что спутник олицетворяет. Например, предположим, в оригинальной таблице Связи в качестве бизнес-ключа был номер счета-фактуры и номер клиента. Три месяца спустя мы добавили местоположение (location) в качестве бизнес-ключа. Первоначально спутник в этой таблице связи представлял только отношения между клиентом и счетом-фактурой. Теперь, после добавления местоположение, информация в Спутнике представляет собой связь между счетом-фактурой, местоположением и клиентом. Степень детализации данных была просто сдвинута на уровень ниже.
Помните, что изменение степени детализации ключа может повлиять на значение данных. Это единственное место, где изменения ключа влияет на нижележащие архитектурные элементы. Если таблица Связи является родительской (экспортирует свой суррогатный ключ в дочернюю таблицу Связь), то изменение бизнес-ключа или степени детализации затронет значение зависимой дочерней Связи. Хорошей новостью является, что имеющийся в настоящее время опыт показывает, наличие, как правило, не более чем двух таблиц Связи, сцепленных вместе (кроме как в модели веб-журнала).
Не путайте изменение в степени детализации с изменением структуры. Если в сущности Связь используются суррогатные ключи, то суррогаты продолжат существовать без изменений. Разница заключается в том, что представляют данные. Таблицы связи вводят много логики соединения для «движка» СУБД? Что происходит с объемом? Как нам управлять различными компонентами, объединяющие данные вместе?
2.4 Операции соединения – проблемы, вопросы и стратегия уменьшения
Таблицы Связи предоставляют парадигме моделирования огромную гибкость и потрясающую ссылочную целостность. Автор считает, что сейчас справедливо обсудить некоторые из отрицательных, широко известных, сторон связей. На первый взгляд можно было бы подумать, что все эти соединения (joins), или архитектура, которая порождает эти соединения, ошибочны или причины проблемы. Однако, посмотрев глубже, мы обнаружим, что это не так. Архитектура не должна быть поставлена под угрозу из-за технологий или проблем низкоуровневой реализации движка. На самом низком уровне (с Data Vault или без), мы обнаруживаем, что у движков (ядер, engine) баз данных всегда были проблемы технологией соединения. Есть несколько движков СУБД, которые хорошо справляются с технологией соединения (но они высокопараллельны (highly parallel) и дорогостоящие).
Смысл заключается в следующем: архитектура не должна адаптироваться под недостатки движков баз данных. Это то место, где большинство производителей баз данных терпят неудачу (если можно так выразиться). Проблема с постоянными структурами «многие ко многим» в этом свете является тяжелым вводом и использует соединения на уровне базы данных.
Большинство сегодняшних систем управления реляционными базами данных (кроме пары) имеют проблемы с соединением информации между таблицами. Вне зависимости от нагрузки, соединения являются наибольшей проблемой в мире оптимизации SQL и в планировании / создании баз данных. Индексов не всегда достаточно для решения проблем соединения. В 3-ей нормальной форме попытка соединить по первичному ключу две 150-миллионостроковых таблицы может вызвать серьезные проблемы производительности. Но по справедливости, выполнение соединения – это функция алгоритмов, работающих на уровне ядра СУБД; это не обязательная функция архитектуры.
Для облегчения проблемы техника моделирования схемы Звезда подразумевала наличие сравнительно небольшого числа строк в измерениях и большого количества строк в таблице фактов. Сегодня это уже заблуждение – так как объемы большинства витрин данных и хранилищ данных выросли со времен оригинального описания изобретения. А витрины данных, состоящие (в среднем) из 15 миллионов строк в измерении Клиент, могут иметь проблемы на небольшой машине, при простом соединении и агрегировании с таблицей фактов в 50 миллионов строк. Поэтому для решения этой проблемы, создаются несколько дополнительных таблиц – агрегаты. Например, ежемесячное перемещение ежедневных данных на агрегированный уровень может быть одним из способов решения этой проблемы. Другим возможным решением является партиционирование таблиц, и это приводит к кошмарам поддержки, проблемам загрузки и трудности в создании новых Схем-Звезд для дополнительных пользовательских нужд.
Проблема соединения все еще остается, только теперь, архитектура приспособлена для преодоления недостатков движков СУБД. В совершенном мире линейной масштабируемостью будут заниматься оборудование и движок СУБД. Представления (выражение select) ежедневных данных и агрегирования их к ежемесячному уровню должно быть достаточно. Если мы рассмотрим эту проблему в Data Vault, то это только усилено. Здесь у нас есть одно возможное оптимальное решение для хранения детальных данных, аффинности данных и гибкости, которое состоит из таблиц, соединенных как многие ко многим. На данном этапе мы должны оказывать давление на производителей СУБД, чтобы они дорабатывали свои движки для более эффективной обработки соединений.
Каково решение в Data Vault?
Сегодняшний обходной путь («work around») или компромисс – не идти на компромиссы в архитектуре, а расширять ее. Схемы Звезда, построенные на основе хранилища Data Vault являются одним из путей решения этих проблем. Предварительное агрегирование данных и их физическое разделение по способам использования (по группам пользователей) будут содействовать уменьшению нагрузки, также как и создание дополнительных денормализованных структур (известных как коллекции на Inner Core: www. coreintegration.com – Library->Data warehousing. Прим. переводчика: видимо много воды утекло на coreintegration.com со времен написания этой статьи; я там не нашел ни библиотеки, не коллекций; если найдете, дайте мне знать, пожалуйста). Другой вариант заключается в покупке высокопараллельной СУБД и использовании представлений (view) на основе Data Vault, чтобы пользоваться данными. Это оказывается чрезвычайно эффективным в плане производительности. Соединения не должны быть скомпрометированы.
Другая возможность заключается в том, чтобы не использовать суррогатные первичные ключи, а использовать по всей модели актуальные бизнес ключи (business key). Из-за этого могут возникнуть другие проблемы: «широкий индекс» («wide-indexes») и широкие данные. Однако, принцип тот же. Существуют система Data Vault, которая создана более 5 лет назад и эксплуатируется в настоящее время, и имеющая бизнес ключи в качестве первичных. Это быстро, эффективно, и позволяет соединить миллион строк с миллионами строк, через текущие состояния спутников, менее чем за 45 минут. Одна из проблем, которая часто обсуждается – это объем.
При преподавании VLDW (очень больших хранилищ данных) в TDWI (data warehouse institute) и в дискуссиях о хранилищах огромных объемов, работающих в режиме близком к реальному времени, прояснился один факт: при приближении к 10 терабайтам (за исключением особых РСУБД) мир архитектуры изменяется, ссылочная целостность ДОЛЖНА быть выключена, и соединения – ошибка, заблуждение. И также хорошо известно, что обработка потоковых данных больших объемов приводит к тем же результатам. В обоих случаях инженерные команды делают те же выводы: надо написать свой собственный C/C++ код для управления функциональностью соединений, операциями над множествами, сжатием и группировкой.
Есть несколько инженерных групп, использующих чрезвычайно денормализованные табличные структуры (не так, как мы привыкли). Это специальная табличная структура построена для NORA (Non Obvious Relationship Associations by SRD – Software Research and Development, Лас-Вегас, Невада). Они используют встроенные в базы данных процессы, и одну большую табличную структуру, чтобы связать информацию и установить взаимосвязь между данными с соединениями в памяти (in-memory joins).
Еще одним потенциальным решением преодоления проблем с соединениями (до решения их производителями СУБД) является создание архитектурных уровней в Data Vault. Обсуждаемые уровни подобны подходу к агрегации данных в витринах данных. Нижний уровень Data Vault будет хранить детальную информацию, каждый вышележащий слой, будет содержать «набор операционного уровня» агрегированный на временной основе: ежедневно, еженедельно, ежемесячно. В запросах будет необходимо указывать, в какой конкретной таблице находится необходимая информация. Эта адаптация Data Vault (с которые я не согласен), необходимая для преодоления механических проблем в движках СУБД. Конечно, другая альтернатива заключается в том, чтобы удалить все связи между таблицами и написать процесс соединения вне базы данных, используя защищенные патентом высоко масштабируемые алгоритмы.
3.0 Заключение
В целом, данная статья – вводный обзор таблиц Связей, их проблем, ограничений и архитектурных причин для их существования. Таблицы Связи часть того, что делает методологию Data Vault такой мощной, масштабируемой и гибкой. Таблица Связь существует для цели, и будет и впредь служить этой цели. Она вызывает душевную боль о СУБД из-за широкомасштабных проблем оптимизации соединений. Хороший DBA может всегда партиционировать, параллелизовать/распараллелить либо оптимизировать критерии соединения. Главное не приносить в жертву архитектуру (убрав Таблицы Связей) только для того, чтобы преодолеть проблемы уровня баз данных. Мы впрочем, выступаем за использование многоуровневых Data Vault с различными уровнями детализации, что вводит понятия свободно масштабируемой архитектуры.
Примите во внимание, что сущность Связь представляют отношения между бизнес-ключами. Эти сущности являются гибкими и могут быть изменены (по ключу), что изменяет смысл Связи и окружающих ее Спутников. Есть несколько проектов Data Vault в стадии реализации, и одна крупная реализация завершена.
Следующая статья серии исследует некоторые из методов запросов, необходимых для извлечения данных из структур Data Vault.